After the first virtual race came the second: Kumo Torakku, which is Japanese for a cloud-shaped truck.
Kumo Torakku
A couple new things got introduced in June. The track came with a city scenery that improved the visual side of it.
The track itself has two irregular-shape 180 degree left turns, one 90 degree left turn and one tight 90 degree right turn. It also has two long straights. There's also more - the lines have changed and now are accompanied by a read and white curb which isn't flat and causes the car to lose grip.
In the previous race we have realised that it was possible to increase the speed above the 5 m/s that the Console allowed for. This month that limit was increased to 8 m/s. Such speed however also causes the car to lose grip and slide.
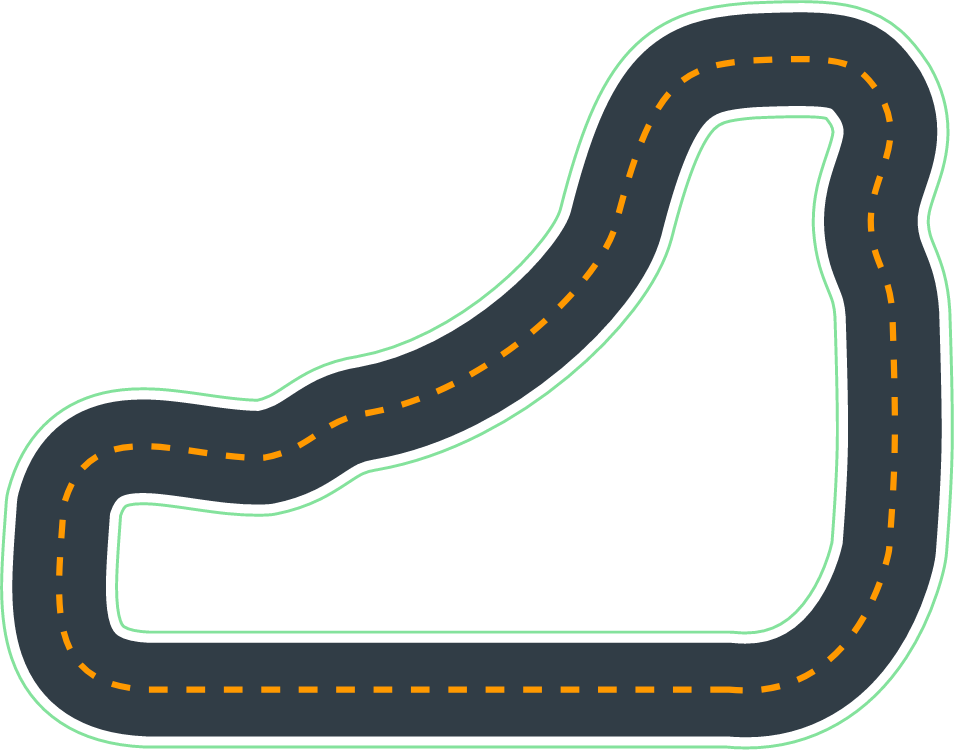
Event that is not all: the evaluation track is different from the training track. In the race the tight 90 degree right turn is replaced with a much milder, slightly turning right section of a track and the 90 degree left turn has a more regular shape.
The training
The evaluation track resembled a re:Invent 2018 track to me, so I decided to use that track and the training one to train - 60-120 minutes on Kumo Torakku, 30-60 minutes on re:Invent, evaluate, repeat.
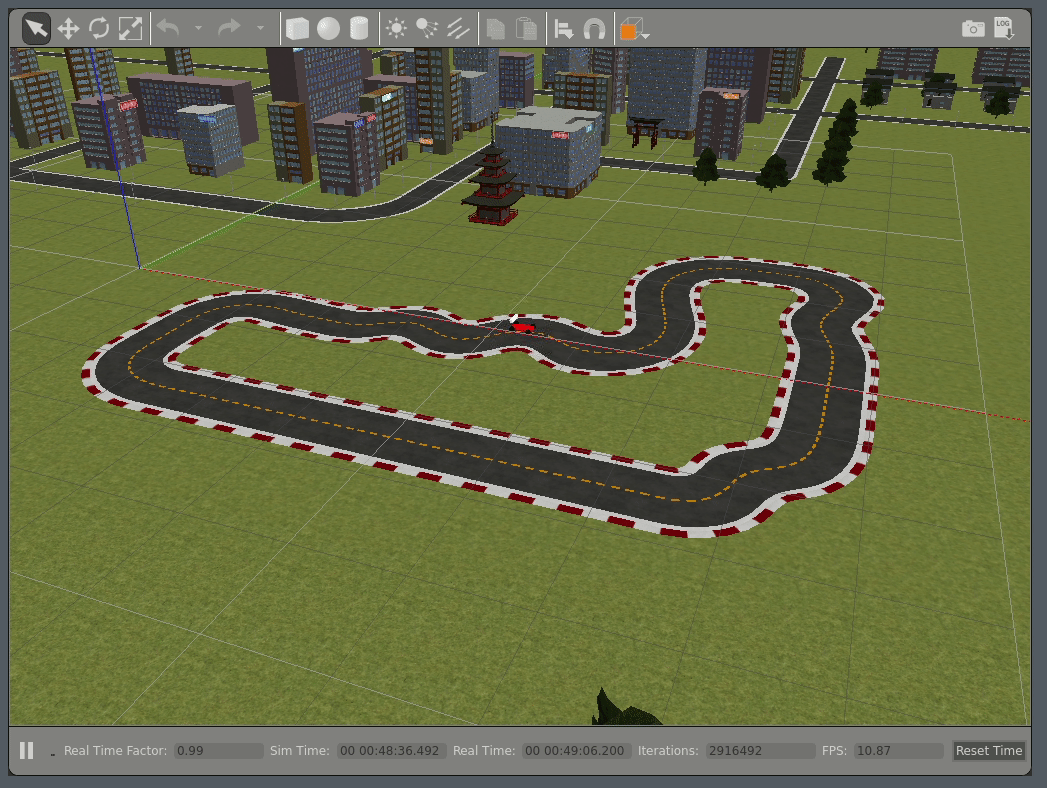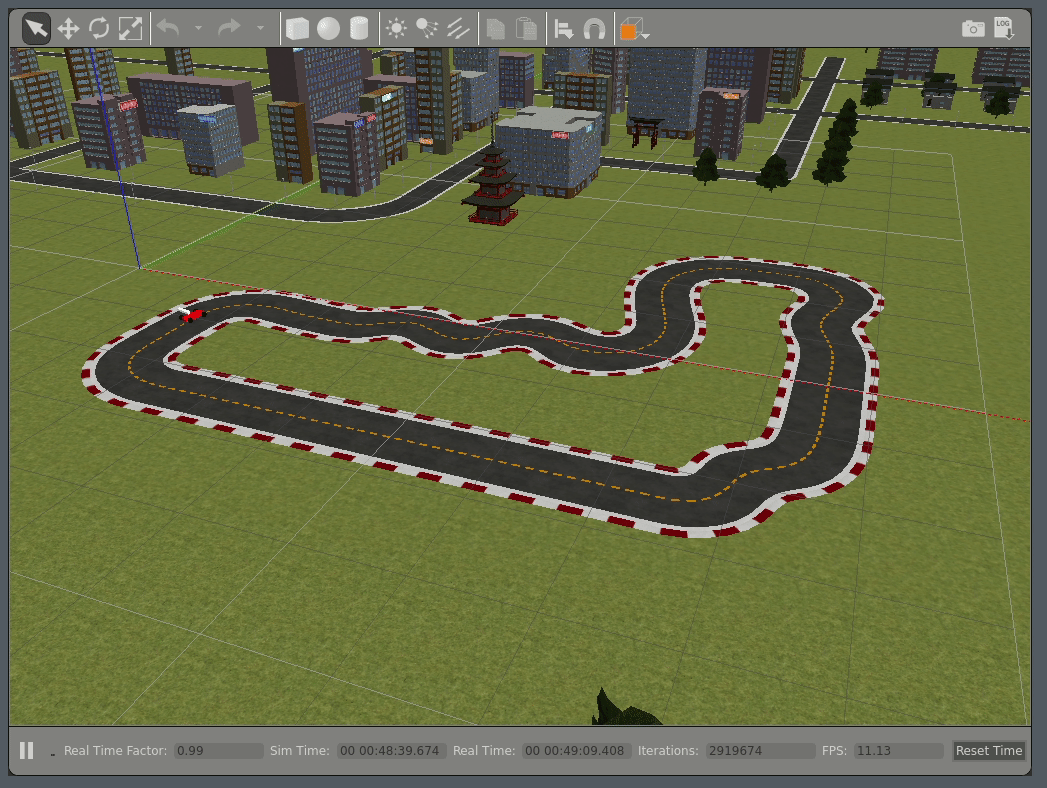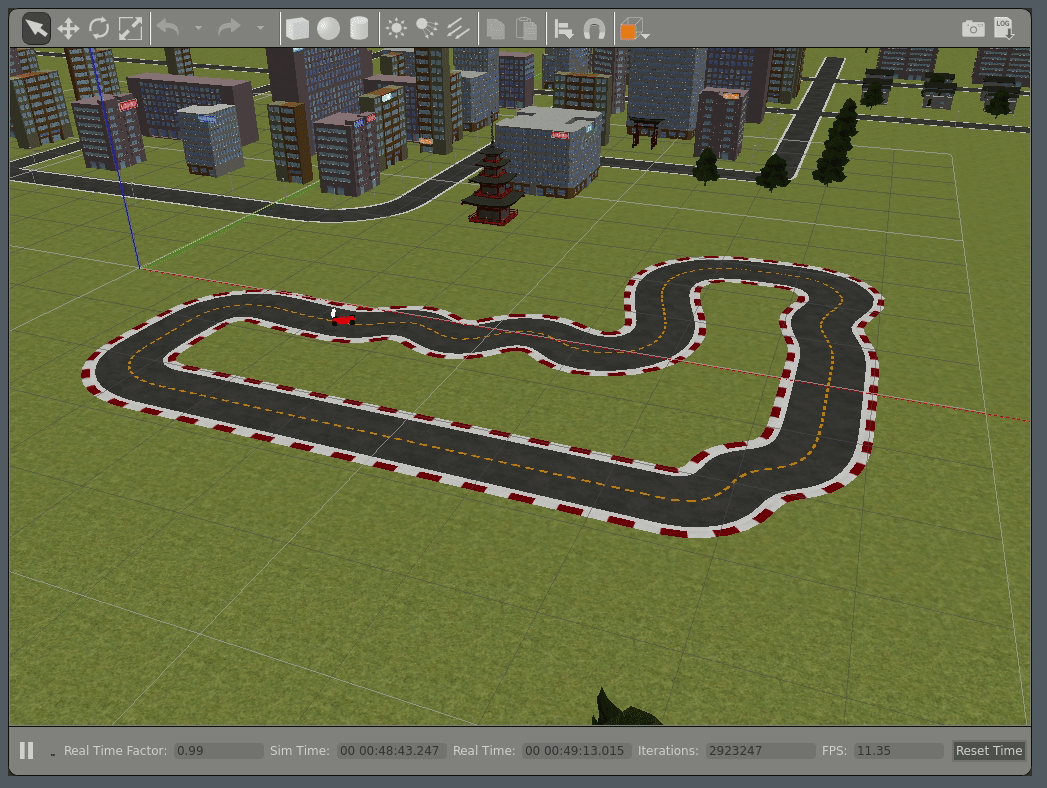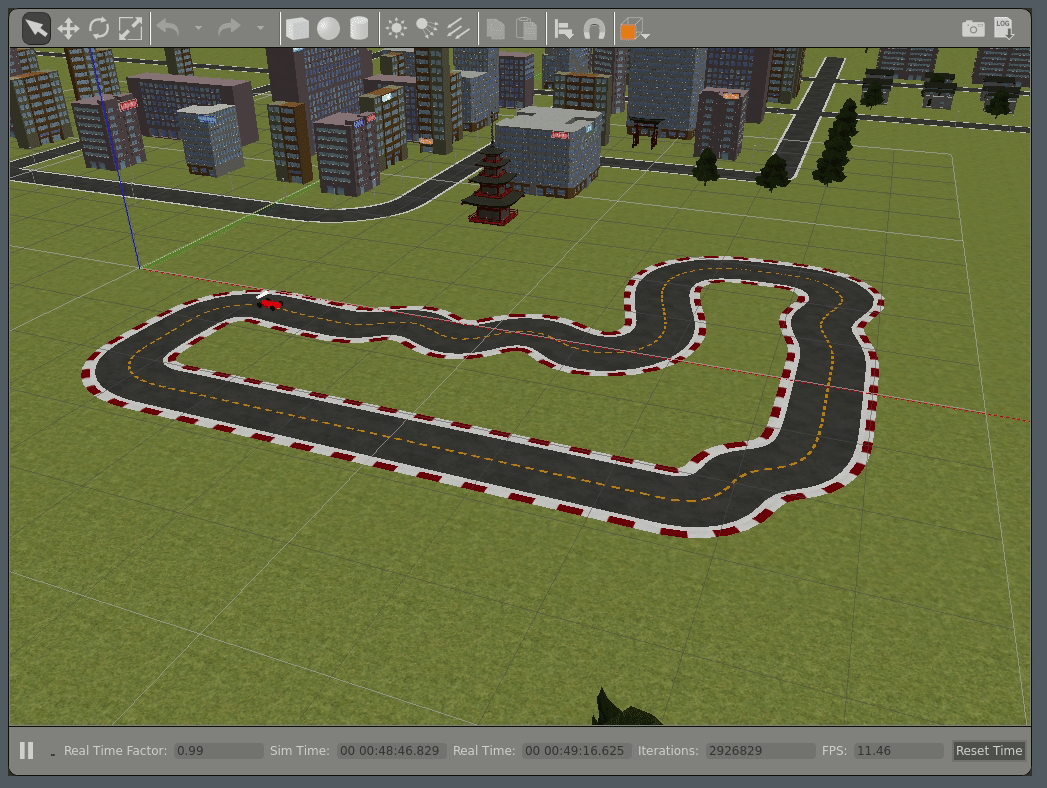
This had a big advantage - I wasn't able to overfit my model to a single track.
Overfitting happens when one trains the car just for a single track and optimises for it only to end up having a model that is not able to steer the car on another track. This was happening in London Loop race and was justified because we were training and evaluating against the same track.
I decided to modify my reward function a bit. I decided to put some expectations of a given track and pieces of desirable behaviour based on a location on the track. While doing so I decided to keep it simple as in just declare where I want the car to go faster etc, not telling it to follow a specific line.
I tried to spend more time analysing the behaviour and rewards and less trying things out at random. The results were very satisfactory - I was able to do a full lap after about 12 hours of training and it was 15.1 seconds one which made me quite happy. That said, at this point I stopped training completely.
In the first week of June a couple changes were introduced to the platform which made the simulation refresh the steps at a same frequency as the real car gets images from the camera, around 15 frames a second. This has caused models before the change to crash. Also, the billing predictions went through the roof. Two things have caused this:
- Kumo Torakku is a much more complex track and as such requires much more resources for the RoboMaker to run
- NAT Gateway was pretty much a hidden cost that was mentioned but not listed. More complex track and more frequent steps meant that the price of its usage went up by a lot
I decided to wait for a resolution since we already knew the DeepRacer Team were trying to come up with one. And I waited. And waited. And waited.
Spoiler: AWS have improved the situation so that it's not as pricey anymore, improved the costing explanation and refunded a lot of the costs.
After over a week of waiting and trying to get some direction going forward, and after a lot lot lot of frustration that went with seeing others work and me being stuck, I decided to set up a local environment. With help from my friends in the community, with some support from my work colleagues and with some investment I finally had a fully working local training environment.
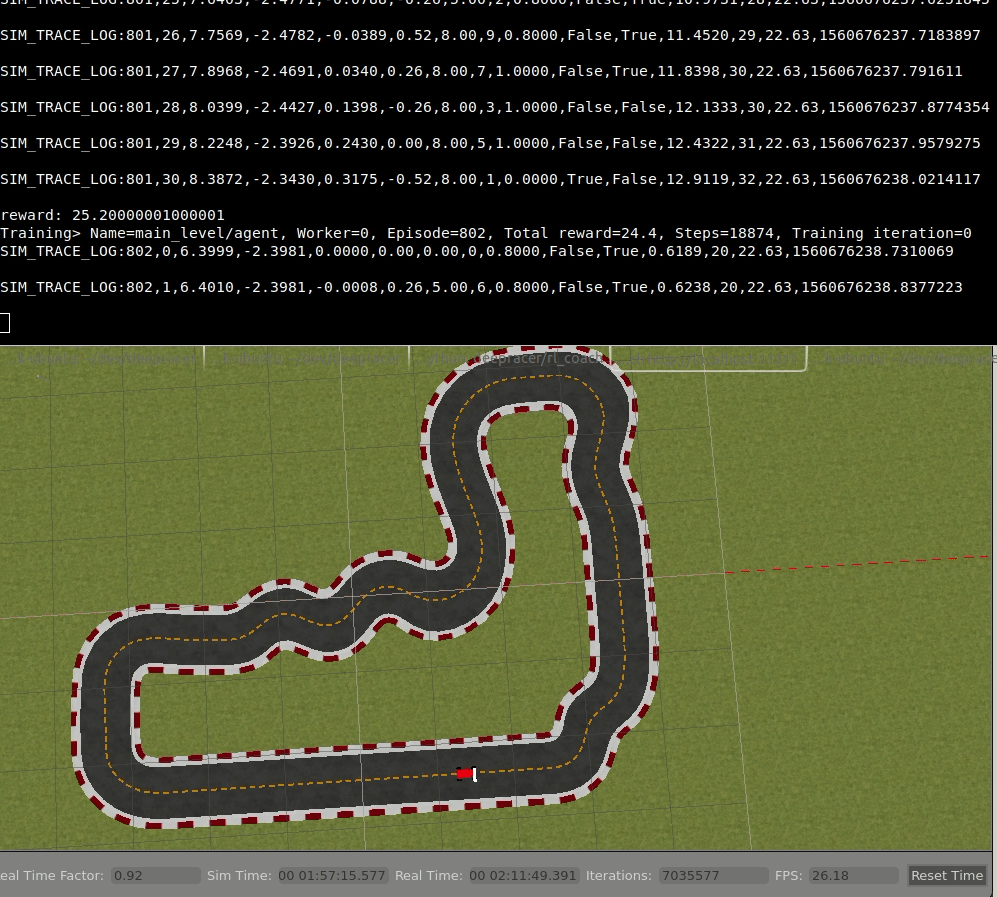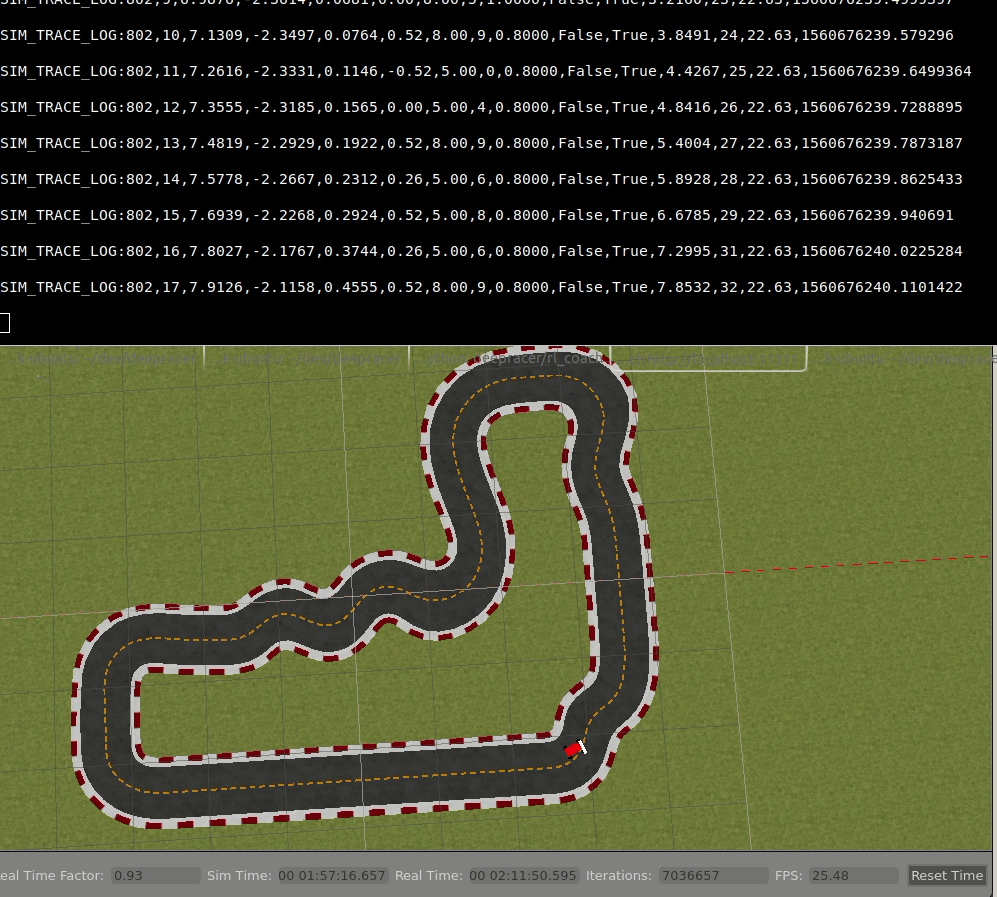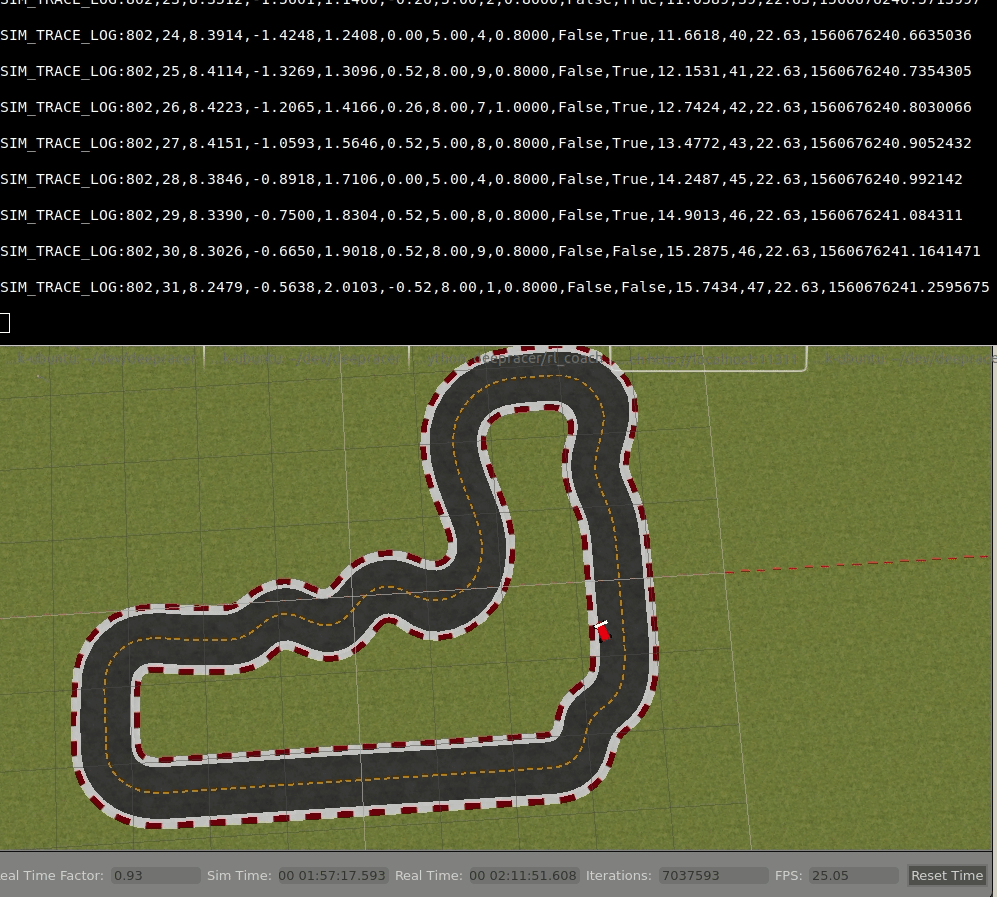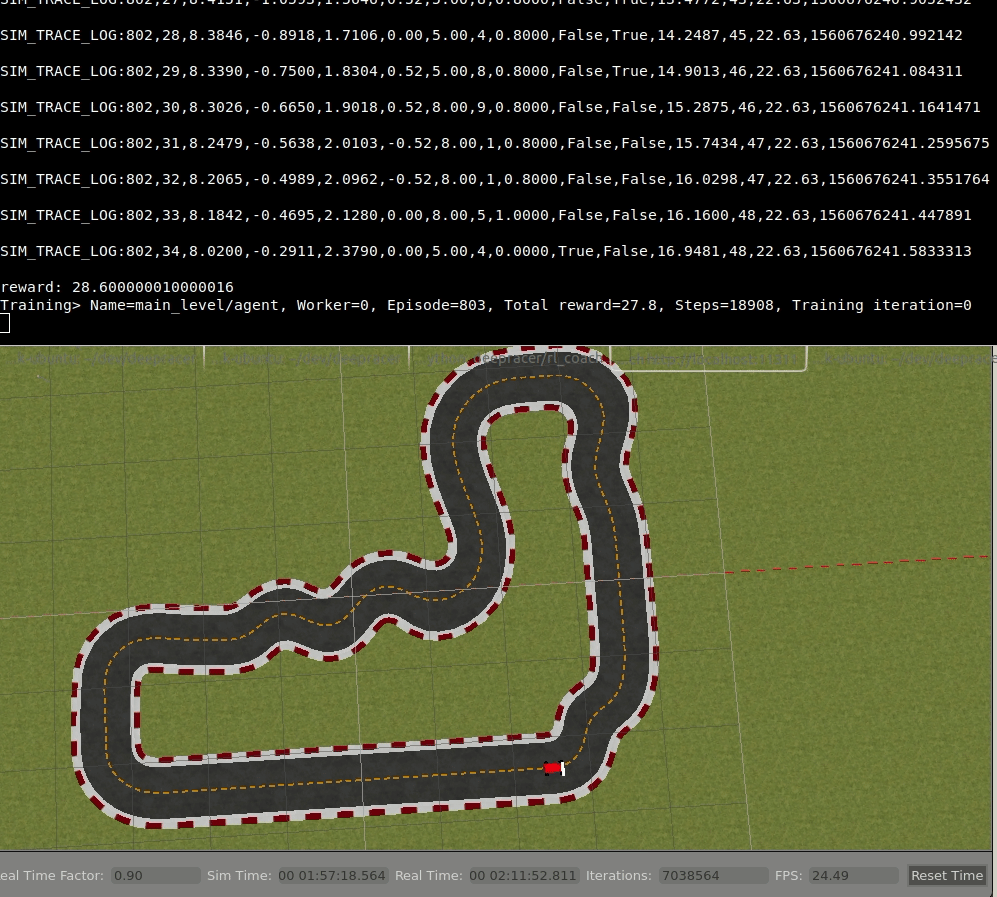
I had an improved reward function and started training, but saw no progress, or at least not enough. I the found that my reward function wasn't optimized enough. I went back and improved it, but then I stopped seeing any progress, I'd even say my training was getting worse. At this point I was already around 40th spot and was feeling the pressure with just three days to go.
To detect progress I used log analysis tool built on top of a Jupyter notebook provided by the DeepRacer Team. I added a new bit to it where I divided the trainings into five buckets and could see how the performance changed over time:
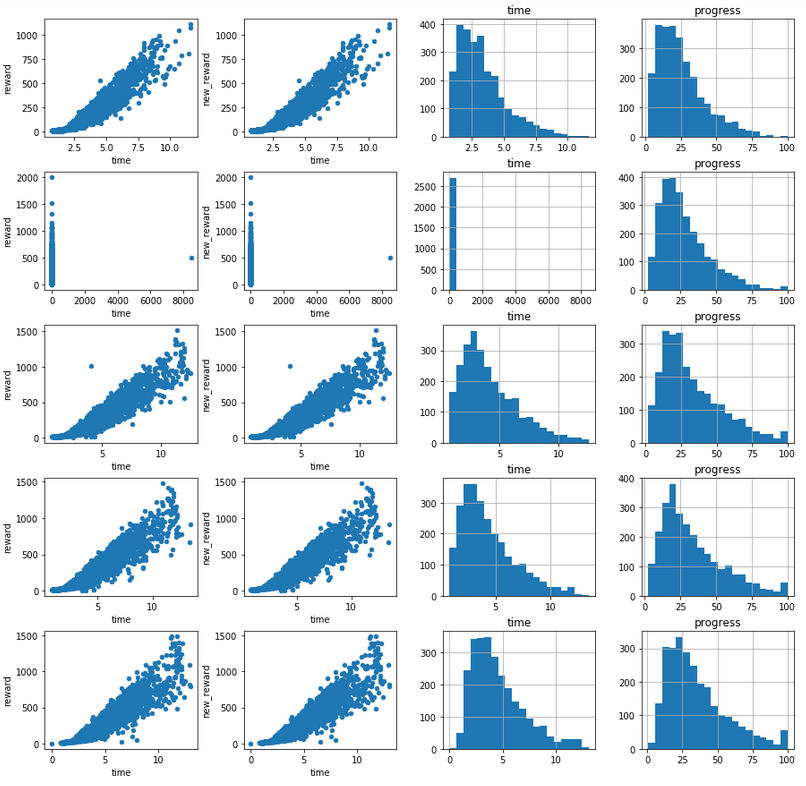
The above is just a sample image, I lost the one showing me losing progress. I stopped learning and didn't really know why and what to do to fix it.
One thing I've noticed was that after changing the reward function my reward values were five times lower. I didn't think it would influence the training, but could it? I didn't have time to start over so I reached for the scrolls to find the ancient Chinese proverb:
Multiply everything by five and see what happens.
I decided to follow the wisdom of those words and you know what? My model converged and I could see such progress on the training track:
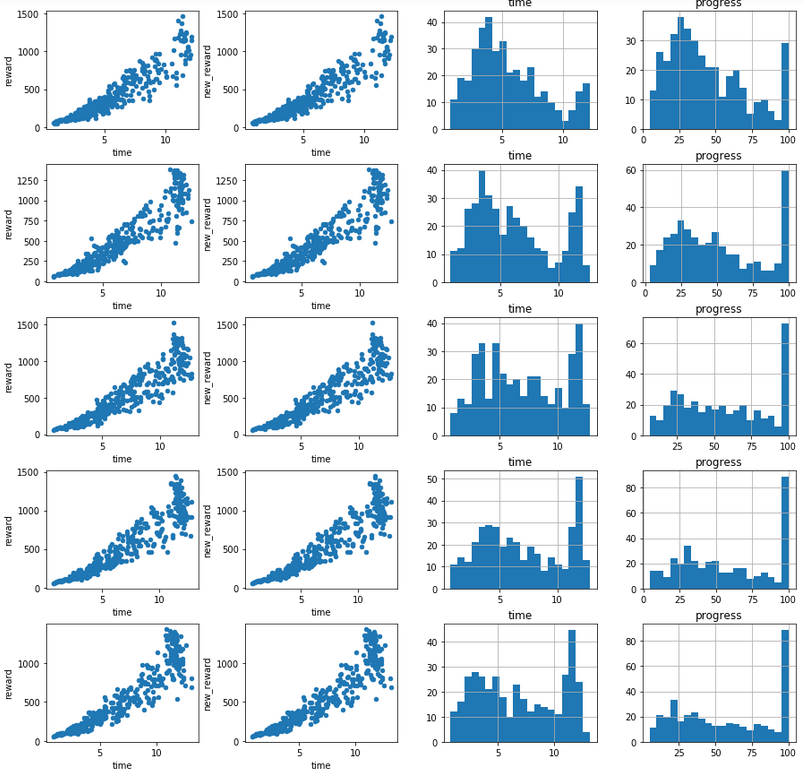
Awesomeness! At the same time I reached a NaN. When the model converges, the improvements decrease until they reach zero difference. As a result some math along the way uses this difference in division, and division by zero gives NaN. And I couldn't move away from it or train away. My model was very strongly fitted for the training track and completed a lot of laps, but couldn't complete the evaluation one. I had to give up with it pretty quickly and turned back to the last successful submission. I checked the training logs and it looks like I couldn't complete too many training laps then, but was able to complete the evaluation one pretty regularly. But how to improve the old model?
Local training gives many advantages. One of them is the ability to alter the action space easily. In the Console one gets something like this:
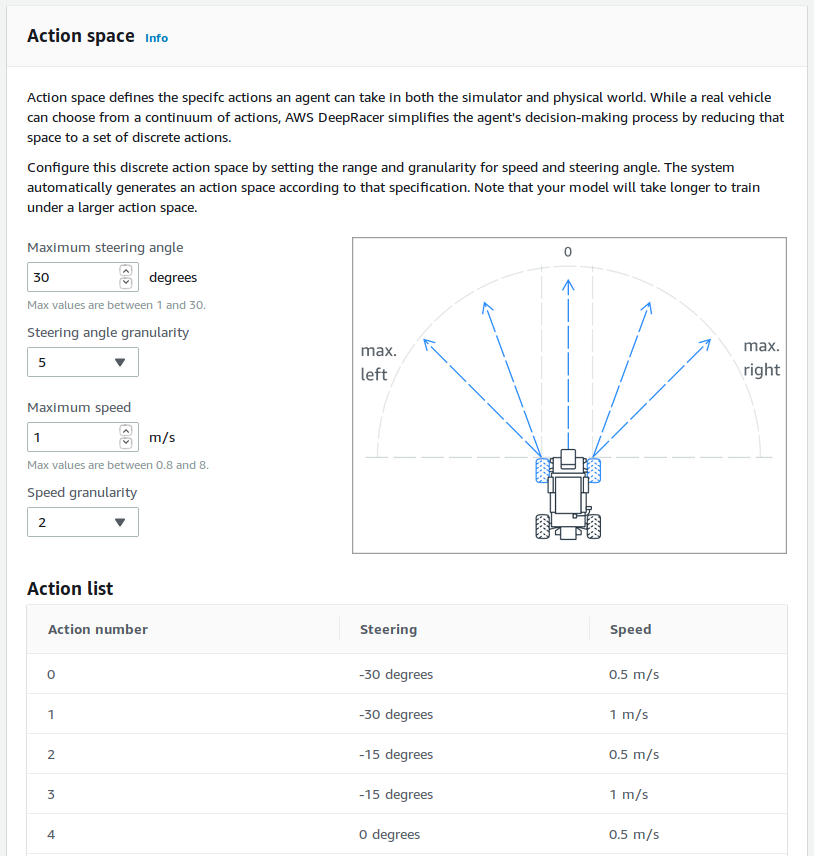
You chose max speed and speed granularity, max turn and turn granularity. This generates a json with three to twenty one evenly spaced actions. What if I don't want evenly spaced actions?
Both in local training and in console it is possible to update the json file. I'm not sure if it is possible to change the count of actions on an already trained model though. I took my reasonably consistent slower model and updated lower speeds to be higher. Then trained it for a short while and submitted. After a couple tries I managed to get 12.6 seconds which put me in a much more favourable place in the top 20. Let me remind you that 18 best performers that didn't win race get invited to compete in the finals as well.
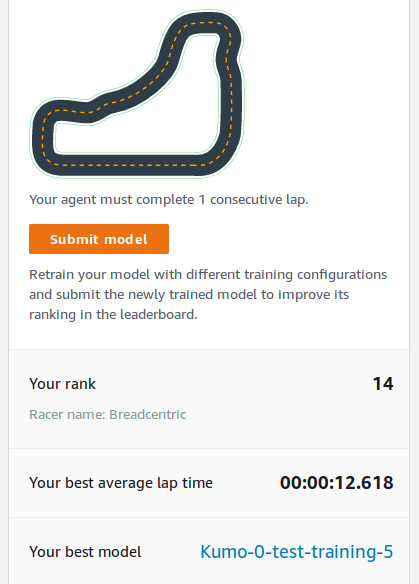
Now with a sigh of relief I could relax. Or could I? What if many come and submit, and improve, and push me further down? Last week was already too intense for me, and I've fallen behind on my final linear algebra assignment that I had to catch up on. The result is a mixture of knowledge, experience, effort, time and luck. Luck is down to trying as often as possible - especially if your model is fast, but not too stable. If only there was an automated way to submit...
Lyndon from the DeepRacer community was trying to backward-engineer the api to submit the models but faced some issues. If only there was a tool to make it simple...
I installed Selenium IDE and within a couple clicks I had a submitter that would try my most recent model repetitively. At that point it meant eighteen more tries or so. I got it running and went to bed. In the morning I woke up to see a time of 11.876 seconds and 10th spot. Lovely!
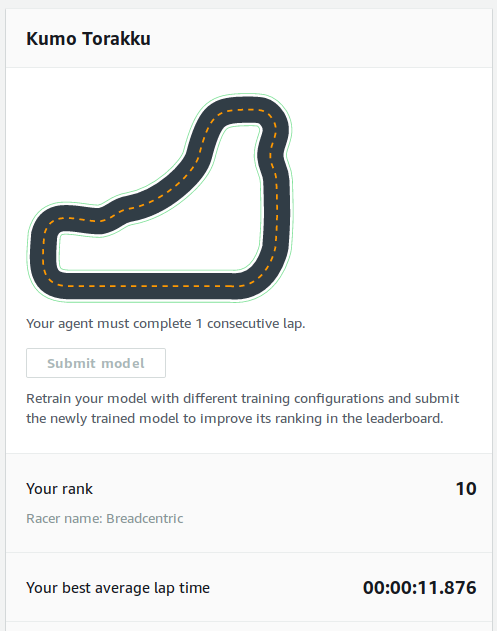
The results
I was happy to finish tenth and equally happy to learn that many members of our community were also quite high in the results.
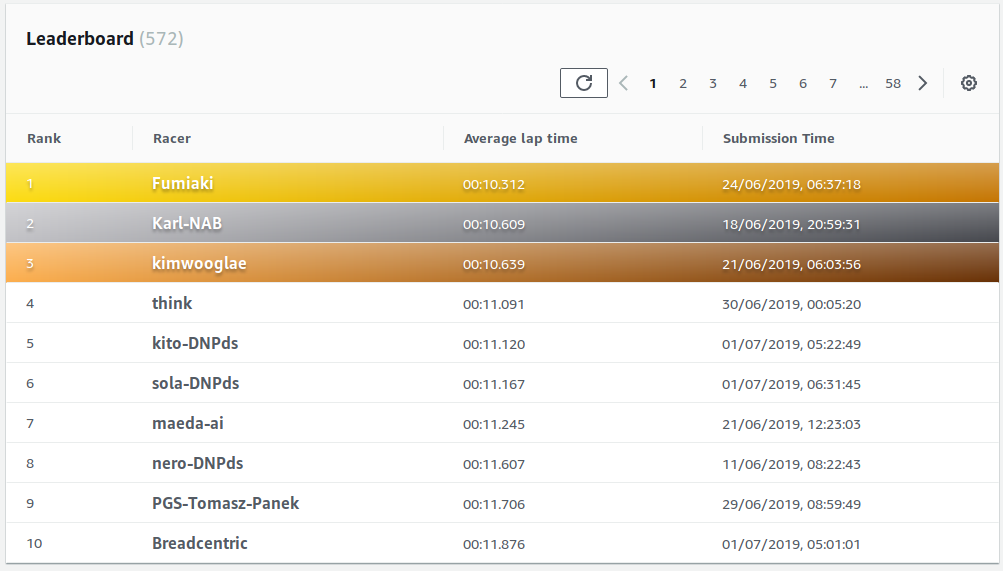
The winner, Fumiaki, totally deserved it. He was also second on the London Loop track, only losing to Karl-NAB, second on Kumo Torakku. In London Loop race places 6-85 had times 12.2-13.2 seconds and this gave pretty much no guarantee for a high spot. This time the differences were much bigger with only places 6-12 within one second and 7.9 seconds difference between places 6-85. This should provide a bit more stability to the overall standings going forward. If I did the maths correctly, I am currently fifth in joint standings:
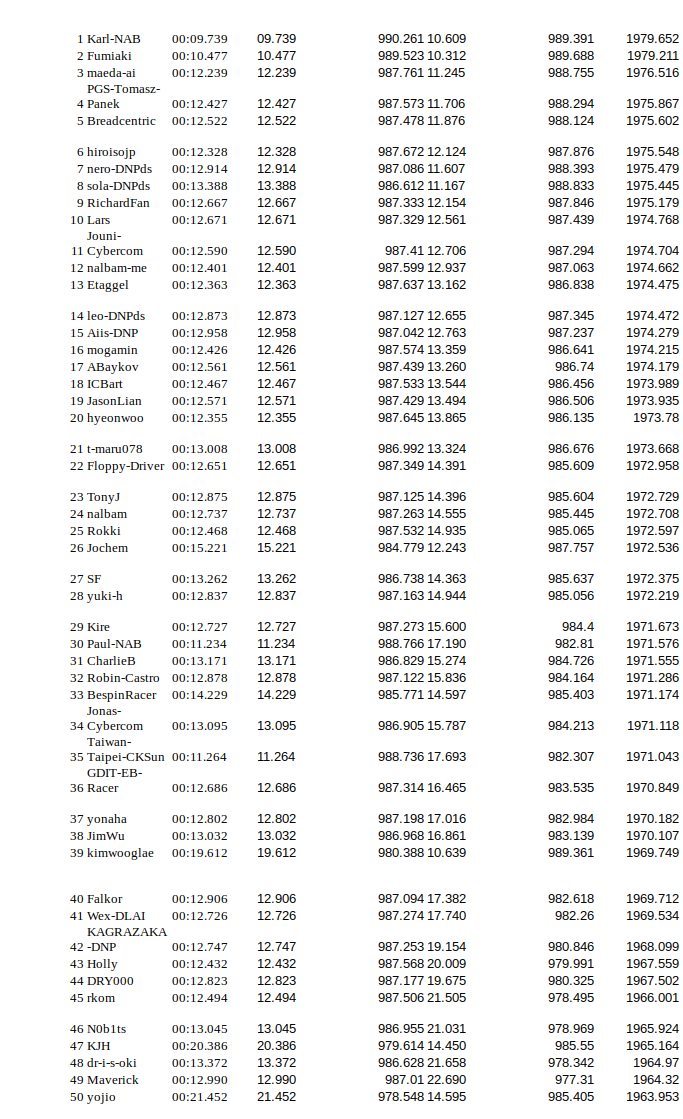
This is my try to compile top 150 results from both races, there may be errors
Let me just add that top two are winners already, and there is a Summit winner from Stokholm in 11th. This gives me a bit of breathing space in the Deep Race To Vegas with 2.6 points advantage over the first person out of the ticket zone. It makes me think that staying within two points of the winner is the best way to secure a spot other than just winning. But winning is harder than not staying too far behind.
Local training environment
It's worth taking the effort and setting up your own environment. Using Chris Rhodes' instructions work you can get started quite quickly, but your CPU may be a bit slow to train. And my laptop sounded like a hair dryer. If you have a gaming computer, you're quite likely set to have a GPU based training env which is much faster. Jonathan Tse provides a set of instructions for this in his article on Medium. The only update is that you may want to use an image from Alex Schultz (The DeepLens Alex). At the time of publishing this article Chris should already pull and publish it with tag nvidia: https://hub.docker.com/r/crr0004/sagemaker-rl-tensorflow/tags - I guess Jonathan will also update the article soon.
The videos
I got futured in two of AWS videos about DeepRacer.
The AWS London Summit DeepRacer TV episode:
The AWS DeepRacer Virtual League promo:
I recommend the DeepRacer TV Playlist for more videos.
Just for completeness, I will also republish the reason why I'm calling Alex The DeepLens Alex:
The Pit Stop
AWS have shared a Pit Stop page with some tips and hints on how to get started and then better at AWS DeepRacer. I was very pleased to see my log-analysis post linked in there.
The Community
As before, I recommend joining our community, here is the link: Click. It got renamed and dropped the "London" part of the name. It stopped being a London community pretty fast, and it's a good thing.
Personal progress
I have completed a course in linear algebra and am starting one in multivariate calculus. They are parts of specialisation called Mathematics in Machine Learning. Once done, there's one more course and then I will need to look more at ML subjects. I'm considering more courses but also a more hands-on approach. We'll see.
The next race
The Empire City Circuit race has already started with some new challenges included. I haven't started training yet.